Un sistema operativo de tiempo real (SOTR o RTOS -Real Time Operating System en inglés), es un sistema operativo que ha sido desarrollado para aplicaciones de tiempo real. Como tal, se le exige corrección en sus respuestas bajo ciertas restricciones de tiempo. Si no las respeta, se dirá que el sistema ha fallado. Para garantizar el comportamiento correcto en el tiempo requerido se necesita que el sistema sea predecible (determinista).
Usado típicamente para aplicaciones integradas, normalmente tiene las siguientes características:
En la actualidad hay un debate sobre qué es tiempo real. Muchos sistemas operativos de tiempo real tienen un programador y diseños de controladores que minimizan los periodos en los que las interrupciones están deshabilitadas, un número llamado a veces duración de interrupción. Muchos incluyen también formas especiales de gestión de memoria que limitan la posibilidad de fragmentación de la memoria y aseguran un límite superior mínimo para los tiempos de asignación y retirada de la memoria.
Un ejemplo temprano de sistema operativo en tiempo real a gran escala fue el denominado «programa de control» desarrollado por American Airlines e IBM para el sistema de reservas Sabre.
Es una falacia creer que este tipo de sistemas operativos es eficiente en el sentido de tener una capacidad de procesamiento alta. El algoritmo de programación especializado, y a veces una tasa de interrupción del reloj alta pueden interferir en la capacidad de procesamiento.
Aunque para propósito general un procesador moderno suele ser más rápido, para programación en tiempo real deben utilizarse procesadores lo más predecibles posibles, sin caché, sin paginación, sin predicción de saltos,... Todos estos factores añaden una aleatoriedad que hace que sea difícil demostrar que el sistema es viable, es decir, que cumple con los plazos.
Hay dos diseños básicos:
El diseño de compartición de tiempo gasta más tiempo de la UCP en cambios de tarea innecesarios. Sin embargo, da una mejor ilusión de multitarea. Normalmente se utiliza un sistema de prioridades fijas.
Uno de los algoritmos que suelen usarse para la asignación de prioridades es el Rate-Monotonic Schedule. Si el conjunto de tareas que tenemos es viable con alguna asignación de prioridades fijas, también es viable con el Rate-Monotonic Schedule, donde la tarea más prioritaria es la de menor periodo. Esto no quiere decir que si no es viable con Rate-Monotonic Schedule no sea viable con asignaciones de prioridad variable. Puede darse el caso de encontrarnos con un sistema viable con prioridades variables y que no sea viable con prioridades fijas.
En los diseños típicos, una tarea tiene tres estados: ejecución, preparada y bloqueada. La mayoría de las tareas están bloqueadas casi todo el tiempo. Solamente se ejecuta una tarea por UCP. La lista de tareas preparadas suele ser corta, de dos o tres tareas como mucho.
El problema principal es diseñar el programador. Usualmente, la estructura de los datos de la lista de tareas preparadas en el programador está diseñada para que cada búsqueda, inserción y eliminación necesiten interrupciones de cierre solamente durante un periodo de tiempo muy pequeño, cuando se buscan partes de la lista muy definidas.
Esto significa que otras tareas pueden operar en la lista asincrónicamente, mientras que se busca. Una buena programación típica es una lista conectada bidireccional de tareas preparadas, ordenadas por orden de prioridad. Hay que tener en cuenta que no es rápido de buscar sino determinista. La mayoría de las listas de tareas preparadas sólo tienen dos o tres entradas, por lo que una búsqueda secuencial es usualmente la más rápida, porque requiere muy poco tiempo de instalación.
El tiempo de respuesta crítico es el tiempo que necesita para poner en la cola una nueva tarea preparada y restaurar el estado de la tarea de más alta prioridad.
En un sistema operativo en tiempo real bien diseñado, preparar una nueva tarea necesita de 3 a 20 instrucciones por cada entrada en la cola y la restauración de la tarea preparada de máxima prioridad de 5 a 30 instrucciones. En un procesador 68000 20MHz, los tiempos de cambio de tarea son de 20 microsegundos con dos tareas preparadas.
Cientos de UCP MIP ARM pueden cambiar en unos pocos de microsegundos.
Las diferentes tareas de un sistema no pueden utilizar los mismos datos o componentes físicos al mismo tiempo. Hay dos diseños destacados para tratar este problema.
Uno de los diseños utiliza semáforos. En general, el semáforo puede estar cerrado o abierto. Cuando está cerrado hay una cola de tareas esperando la apertura del semáforo.
Los problemas con los diseños de semáforos son bien conocidos: inversión de prioridades y puntos muertos.
En la inversión de prioridades, una tarea de mucha prioridad espera porque otra tarea de baja prioridad tiene un semáforo. Si una tarea de prioridad intermedia impide la ejecución de la tarea de menor prioridad, la de más alta prioridad nunca llega a ejecutarse. Una solución típica sería tener a la tarea que tiene el semáforo ejecutada a la prioridad de la tarea que lleva más tiempo esperando.
En un punto muerto, dos tareas tienen dos semáforos pero en el orden inverso. Esto se resuelve normalmente mediante un diseño cuidadoso, realizando colas o quitando semáforos, que pasan el control de un semáforo a la tarea de más alta prioridad en determinadas condiciones.
La otra solución es que las tareas se manden mensajes entre ellas. Esto tiene los mismos problemas: La inversión de prioridades tiene lugar cuando una tarea está funcionando en un mensaje de baja prioridad, e ignora un mensaje de más alta prioridad en su correo. Los puntos muertos ocurren cuando dos tareas esperan a que la otra responda.
Aunque su comportamiento en tiempo real es menos claro que los sistemas de semáforos, los sistemas basados en mensajes normalmente se despegan y se comportan mejor que los sistemas de semáforo.
Las interrupciones son la forma más común de pasar información desde el mundo exterior al programa y son, por naturaleza, impredecibles. En un sistema de tiempo real estas interrupciones pueden informar diferentes eventos como la presencia de nueva información en un puerto de comunicaciones, de una nueva muestra de audio en un equipo de sonido o de un nuevo cuadro de imagen en una videograbadora digital.
Para que el programa cumpla con su cometido de ser tiempo real es necesario que el sistema atienda la interrupción y procese la información obtenida antes de que se presente la siguiente interrupción. Como el microprocesador normalmente solo puede atender una interrupción a la vez, es necesario que los controladores de tiempo real se ejecuten en el menor tiempo posible. Esto se logra no procesando la señal dentro de la interrupción, sino enviando un mensaje a una tarea o solucionando un semáforo que está siendo esperado por una tarea. El programador se encarga de activar la tarea y esta se encarga de adquirir la información y completar el procesamiento de la misma.
El tiempo que transcurre entre la generación de la interrupción y el momento en el cual esta es atendida se llama latencia de interrupción. El inverso de esta latencia es una frecuencia llamada frecuencia de saturación, si las señales que están siendo procesadas tienen una frecuencia mayor a la de saturación, el sistema será físicamente incapaz de procesarlas. En todo caso la mayor frecuencia que puede procesarse es mucho menor que la frecuencia de saturación y depende de las operaciones que deban realizarse sobre la información recibida.
Hay dos problemas con el reparto de la memoria en SOTR (sistemas operativos en tiempo real).
El primero, la velocidad del reparto es importante. Un esquema de reparto de memoria estándar recorre una lista conectada de longitud indeterminada para encontrar un bloque de memoria libre; sin embargo, esto no es aceptable ya que el reparto de la memoria debe ocurrir en un tiempo fijo en el SOTR.
En segundo lugar, la memoria puede fragmentarse cuando las regiones libres se pueden separar por regiones que están en uso. Esto puede provocar que se pare un programa, sin posibilidad de obtener memoria, aunque en teoría exista suficiente memoria. Una solución es tener una lista vinculada LIFO de bloques de memoria de tamaño fijo. Esto funciona asombrosamente bien en un sistema simple.
La paginación y la caché suelen desactivarse en los sistemas en tiempo real, ya que son un factor bastante aleatorio e impredecible, que varía el tiempo de respuesta y no nos permite asegurar que se cumplirán los plazos.
Para las comunicaciones se suelen usar redes CAN_bus, ya que las redes más usuales, como Ethernet son indeterministas y no pueden garantizarnos el tiempo de respuesta.
QNX proporciona:
QNX logra su único grado de eficacia, modularidad, y simplicidad a través de dos principios fundamentales:
QNX consiste en un kernel pequeño a cargo de un grupo de procesos cooperativos.
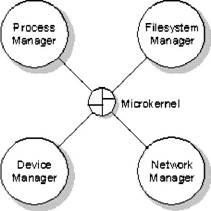
Un verdadero kernel
El Microkernel se dedica sólo a dos funciones:
En el scheduling se entra sólo como el resultado directo de llamadas del kernel, ya sea de un proceso o de una interrupción del hardware.
Todos los servicios, excepto aquellos proporcionados por el Microkernel, se manejan como procesos comunes. Una configuración de QNX típica tiene los siguientes procesos de sistema (los cuales no forman parte del microkernel):
Los drivers de dispositivos son procesos que protegen al sistema operativo de tratar con todos los detalles requeridos para soportar hardware específico.
Cualquier proceso en cualquier máquina en la red puede hacer uso de cualquier recurso directamente en cualquier otra máquina. De la perspectiva de la aplicación, no hay ninguna diferencia entre un recurso local o remoto.
SMP (Symmetric Multi-Processing) normalmente asociados a UNIX o NT, puesto que estos grandes kernels contienen la mayor parte de los servicios del sistema operativo, los cambios para soportar SMP son extensos, introduciendo muchas modificaciones en el código.
QNX por otro lado, contiene un microkernel muy pequeño rodeado por procesos que actúan como administradores de recursos, por ejemplo: sistemas de archivos, I/O, red. Modificando solo el microkernel, todos los demás servicios del sistema operativo ganarán inmediatamente una ventaja de SMP sin necesidad de cambios en el código.
El Microkernel de QNX es responsable de lo siguiente:
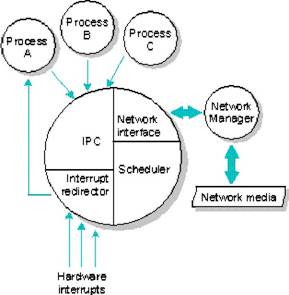
El Microkernel de QNX soporta tres tipos de IPC: mensajes, proxies y señales
El intercambio de mensajes no solo permite a los procesos pasarse datos entre ellos, sino que también proporciona un medio de sincronizar la ejecución de varios procesos que cooperan mutuamente.
Una aplicación de QNX puede hablar con un proceso en otra computadora en la red como si estuviera hablando con otro proceso en la misma máquina. De la perspectiva de la aplicación, no hay ninguna diferencia entre un recurso local y remoto. Este grado de transparencia es posible debido a los circuitos virtuales (VC), los cuales son caminos que el Administrador de Red proporciona para transmitir mensajes, proxies, y señales por la red.
El scheduler del Microkernel toma las decisiones de planificación cuando:
A cada proceso se le asigna una prioridad. El scheduler selecciona el próximo proceso para correr mirando la prioridad asignada a cada proceso que está en la cola de LISTOS (un proceso en la cola de LISTOS es uno capaz de usar el CPU). El proceso con la prioridad más alta se selecciona para ejecutarse.
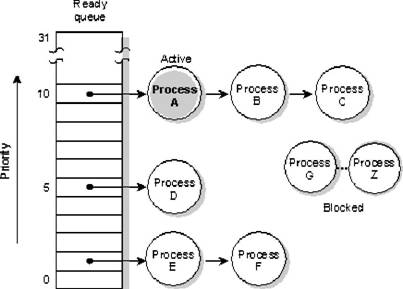
Los otros procesos (G-Z) están BLOQUEADOS. El proceso A está corriendo actualmente. Los procesos A, B, y C están en la prioridad más alta. Las prioridades asignadas al rango de procesos son de 0 (el más bajo) a 31 (el más alto). Se hereda la prioridad predefinida del padre a un proceso hijo.
Para satisfacer las necesidades de varias aplicaciones, QNX proporciona tres métodos de planificación:
Cada proceso en el sistema puede correr usando cualquiera de estos métodos. Recuerde que estos métodos de scheduling sólo se aplican cuando dos o más procesos que comparten la misma prioridad están LISTOS. Si un proceso de prioridad superior se pone en LISTO, desaloja todos los procesos de baja-prioridad inmediatamente.
En FIFO, un proceso seleccionado para correr continúa ejecutándose hasta que:
Dos procesos que corren a la misma prioridad pueden usar FIFO para asegurar la exclusión mutua a un recurso compartido. Ningún proceso será desalojado por otro mientras se está ejecutando.
En Round-robin un proceso seleccionado para correr continúa ejecutando hasta que:
Un Quantum (o Timeslice) es la unidad de tiempo asignada a cada proceso. Una vez que consume su quantum, un proceso se desaloja y el próximo proceso LISTO al mismo nivel de prioridad se le da el control. Un quantum es de 50 milliseconds.
En la planificación adaptativa, un proceso se comporta como sigue:
Usted puede usar la planificación adaptativa en ambientes dónde los procesos son del tipo background en su mayoría y están compartiendo la computadora con los usuarios interactivos. La planificación adaptativa es el método de planificación predefinido para programas creados por la SHELL.
Tiene el siguiente comportamiento (otra explicación de planificación adaptativa). Si el proceso consume su timeslice y existe otro proceso de igual prioridad en estado READY, el proceso reduce su prioridad en 1. Si el proceso tiene una prioridad inferior a la original y no recibe el control por 1 segundo, su prioridad aumenta en 1, pero nunca sobrepasa la prioridad inicial.
Si el proceso se bloquea en algún estado, obtiene inmediatamente su prioridad original.
Es el tiempo de la recepción de una interrupción del hardware, hasta que se ejecuta la primera instrucción de un manipulador de interrupción de software. Ciertas secciones críticas de código requieren que se desactive temporalmente las interrupciones. El máximo tiempo de desactivación de las interrupciones define la latencia de interrupción del peor caso, en QNX es muy pequeño. La tabla siguiente muestra las Til típicas:
| Latencia de interrupciones | Procesador: |
| 3.3 microsec | 166 Pentium de MHz |
| 4.4 microsec | 100 Pentium de MHz |
| 5.6 microsec | 100 MHz 486DX4 |
| 22.5 microsec | 33 MHz 386EX |
Es el tiempo entre la terminación del manipulador de interrupción y la ejecución de la primera instrucción de un proceso del driver. Esto significa el tiempo que toma cambiar el contexto del proceso actualmente ejecutando y restaurar el contexto del proceso del driver requerido. Es más grande que la latencia de la interrupción.
| Latencia de interrupciones | Procesador: |
| 4.7 microsec | 166 Pentium de MHz |
| 6.7 microsec | 100 Pentium de MHz |
| 11.1 microsec | 100 MHz 486DX4 |
| 74.2 microsec | 33 MHz 386EX |
Aunque comparte el mismo espacio de dirección con el Microkernel, este realiza scheluding sobre él. El Administrador del Procesos es responsable de crear nuevos procesos en el sistema y manejar los recursos más fundamentales asociados con un proceso. Estos servicios son proporcionados vía mensajes. Por ejemplo, si un proceso corriente quiere crear un nuevo proceso, envía un mensaje que contiene los detalles del nuevo proceso a ser creado.
Primitivas de creación de procesos:
Un proceso pasa por cuatro fases:
Un proceso siempre está en uno de los estados siguientes:
Los procesos pueden tener nombres simbólicos, en el contexto de un solo nodo, los procesos pueden registrar este nombre con el Administrador de Procesos en el nodo dónde ellos se están ejecutando. Otros procesos pueden pedirle el PID asociado a ese nombre entonces al Administrador del Procesos.
La administración de tiempo se basa en un cronómetro del sistema mantenido por el sistema operativo. Un proceso puede crear timers, puede armarlos con un intervalo de tiempo, y puede quitar los mismos. La precisión del cronómetro
Ellos reaccionan a las interrupciones del hardware y manejan el traslado de bajo nivel de datos entre la computadora y los dispositivos externos. Son empaquetados físicamente como la parte de un proceso QNX normal (por ejemplo un Driver), pero ellos siempre corren asincrónicamente con el proceso asociado con ellos.
Un manipulador de interrupciones:
Varios procesos se pueden atar a la misma interrupción (si es soportado por el hardware). Cuando una interrupción física ocurre, se le dará el mando a cada manipulador de interrupción de a uno a la vez.
El filesystem de QNX es optativo, el espacio del pathname no se construye en el filesystem como en la mayoría de los sistemas monolíticos.
El espacio del pathname es dividido en regiones de autoridad. Cualquier proceso que desea proporcionar los servicios de I/O orientado a archivos registrará un prefijo con el Administrador de Procesos que define la porción del espacio de nombres que él desea administrar (es decir su región de autoridad). Por ejemplo, el Administrador de Dispositivos (Dev) normalmente registra el prefijo /dev. Estos prefijos constituyen un árbol de prefijos que se mantiene en la memoria en cada computadora que corre QNX.
Cuando un proceso abre un archivo, el pathname del archivo es aplicado contra el árbol de prefijos para direccionar el OPEN () al Administrador de recursos I/O apropiado.
Por ejemplo, el Administrador de Dispositivos de carácter (Dev) normalmente registra el prefijo /dev. Si un proceso llama OPEN () con /dev/xxx, una concurrencia con el prefijo de /dev ocurrirá y OPEN () se redireccionará a Dev (su dueño).
Una segunda forma de prefijo, es conocida como un alias, es una simple substitución de un string para un prefijo. Un alias es de la forma:
Prefijo =string reemplazante
Por ejemplo, asuma usted está corriendo en una máquina que no tiene un filesystem local (no hay ningún proceso que administre" /"). Sin embargo hay un filesystem, en otro nodo (diga el 10) que usted desea acceder como" /". Esto se logra usando el prefijo del seudónimo siguiente:
/ = / /10 /
Usted también puede usar alias para crear nombres de dispositivos especiales. Por ejemplo, si un spooler de impresión estuviera corriendo en el nodo 20, usted puede poner un pathname de la copiadora local como un alias a este de la siguiente forma:
/dev/printer=//20/dev/spool.
Cualquier demanda para abrir /dev/printer se dirigirá por la red al spooler real.
Una vez que un recurso de I/O se ha abierto, un espacio de nombres diferente entra en acción. OPEN () retorna un entero llamado descriptor de archivo (FD) qué se usa para dirigir todas las demandas de I/O a ese Administrador. El espacio de nombres de descriptor de archivos es completamente local a cada proceso. El Administrador usa una combinación de un PID y FD para identificar la estructura de control asociada con la llamada OPEN () anterior. Esta estructura se llama Open Control Block (OCB) y esta contenida dentro del Administrador de I/O.
El siguiente diagrama muestra un Administrador de I/O que toma un PID, FD y los mapea trazando los OCB.
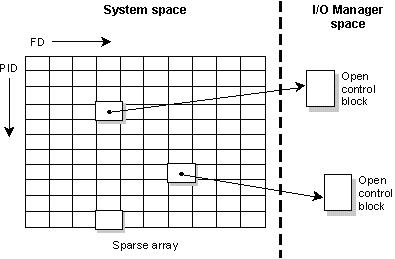
El PID y FD trazan a un OCB de un Administrador de I/O.
El OCB contiene la información activa sobre el recurso abierto. Por consiguiente, si un proceso abre el mismo archivo dos veces, cualquier llamada al lseek () usando un FD no afectará el punto seek del otro FD.
Lo mismo es válido para la apertura del mismo archivo por diferentes procesos. El siguiente diagrama muestra dos procesos, en el cuál un proceso abre el mismo archivo dos veces, y el otro lo abre una vez. No hay ningún FD compartido.
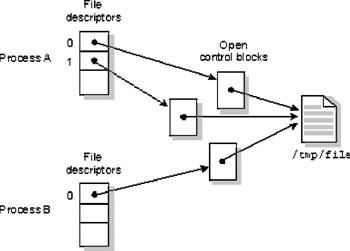
Diversos FD en uno o más procesos pueden referirse al mismo OCB. Esto se cumple cuando:
Cuando varios FD se refieren al mismo OCB, cualquier cambio en el estado del OCB se ve inmediatamente en todos los procesos que tienen el descriptor de archivo unido al mismo OCB.
El siguiente diagrama muestra dos procesos, en el cuál uno abre un archivo dos veces, entonces hace un dup() para conseguir un tercero. El proceso crea a un hijo que hereda todos los archivos abiertos.
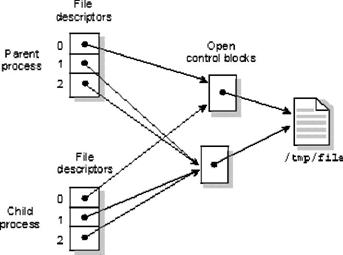
Se puede prevenir que un DF pueda heredarse cuando usted llama a un SPAWN () o exec () llamando a la función fcntl () y seteando la bandera de FD_CLOEXEC.
El Administrador de Filesystem (Fsys) proporciona un método estándar para guardar y acceder a los datos en los subsistemas de discos. Fsys se ocupa de todas las demandas de abrir, cerrar, leer, y escribir sobre los archivos.
Un archivo es un objeto que puede escribirse, leerse, o ambos. QNX implementa seis tipos de archivos; de los cuales cinco de éstos son manejados por Fsys:
El sexto tipo de archivo, el archivo especial de caractér, se maneja por el Administrador de Dispositivos.
El Fsys mantiene cuatro tiempos diferentes de fecha por cada archivo:
El acceso a los archivos regulares y a los directorios es controlado por una tabla de almacenamiento llamada inode. (Véase la sección de "Enlaces y inodes"). Hay tres calificadores de acceso:
Un proceso también puede correr con el user ID o el group ID de un archivo en lugar de aquellos de su proceso padre. El mecanismo que permite que este se conoce como setuid (coloca el ID de usuario en ejecución) y setgid (coloca el ID de grupo en ejecución).
QNX ve un archivo regular como una secuencia de bytes en forma aleatoria que no tienen una estructura interna predefinida. Los programas de aplicación son los responsables de interpretar la estructura y contenido del archivo regular.
Un directorio es un archivo que contiene entradas de directorio. Cada entrada de directorio asocia un nombre de archivo con un archivo. Un nombre de archivo es el nombre simbólico que permite identificar y acceder a un archivo. Un archivo puede ser identificado por más de un nombre de archivo.

Aunque un directorio se comporta como un archivo estándar, el Administrador del sistema de archivos impone algunas restricciones a las operaciones que se pueden realizar en un directorio. En concreto, no se puede abrir un directorio para escribir en él, ni se puede vincular a un directorio con el enlace ().
Para leer las entradas de un directorio, se utiliza un conjunto de funciones definidas por POSIX, que permiten acceder a las entradas de un directorio en forma independiente al SO. Estas funciones incluyen:
En QNX, se guardan archivos regulares y archivos del directorio como una sucesión de extends. Un extend es un conjunto de bloques consecutivos en el disco.
Donde se guardan los extends
Archivos que tienen sólo un extend almacenan la información del mismo en la entrada del directorio. Pero si más de un extend se necesita para almacenar el archivo, la información de éste se guarda en uno o más bloques extends anidados. Cada bloque extend puede sostener información de localización para 60 extends.
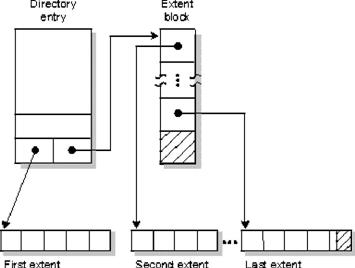
Un archivo que consiste en múltiples regiones consecutivas en un disco – Se conocen como extends en QNX.
Los archivos de datos pueden ser referenciados por más de un nombre. A cada nombre de archivo se lo llama link. (Hay dos tipos de links: links duros a los que nosotros simplemente nos referimos como "links" y los simbolic links).
El nombre del archivo está separado de la información que describe al archivo. La información que no pertenece al nombre del archivo se guarda en una tabla de almacenamiento llamada inode ("nodo de información").
Si un archivo tiene sólo un link (es decir un nombre de archivo), la información del inode se guarda en la entrada del directorio para el archivo. Si el archivo tiene más de un link, el inode se guarda como un registro en un archivo especial nombrado / .inodes, tal como se guardan en las entradas del directorio del archivo que apuntan al registro inode.
Sólo se puede crear un link a un archivo si el archivo y el link están en el mismo filesystem.
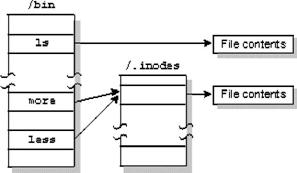
El mismo archivo es el referenciado por dos links llamados "more" y "less".
Hay otras dos situaciones en las que un archivo puede tener una entrada en el archivo de /.inodes:
Cuando un archivo es creado, se inicializa un contador de links que es inicializado en uno. A medida que se agregan links al archivo, este contador de links se incrementa; cuando se remueven el contador de links se decrementa. El espacio que ocupa en el disco el archivo no puede ser liberado a menos que el contador de links sea igual a cero y que todos los programas que usan el archivo lo hayan cerrado. Esto permite que un archivo abierto pueda seguir siendo utilizado aun cuando se hayan removido todos los links.
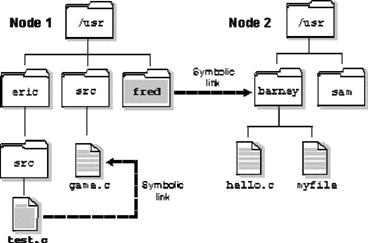
Es un archivo especial que tiene un pathname como dato (una ruta como dato, por .ej. tiene como dato, c:\windows\system32 \sol.exe). Cuando el simbolic links es nombrado en un I/O pedido - por open (), por ejemplo - la parte del pathname del link se reemplaza por los "datos" del simbolic link y el path se reevalúa. Los simbolic links son medios flexibles de indirección del pathname y se usan a menudo para proporcionar caminos múltiples a un solo archivo. Al contrario que los links duros, estos pueden cruzar filesystems y también pueden crear links a directorios.
/ /1/usr/eric/src/test.c--> / /1/usr/src/game.c
El PID y FD trazan a un OCB de un Administrador de I/O.
Recuerde que al eliminar un simbolics links se esta actuando sobre el link, no sobre el archivo. Ya que los simbolics links pueden apuntar a directorios, las configuraciones incorrectas pueden producir problemas como links de directorios circulares. Para recuperarse de los links circulares, el sistema impone un límite en el número de saltos.
Un pipe es un archivo anónimo que sirve como un canal de I/O entre dos o más procesos que cooperan - un proceso escribe en el pipe y el otro lee del mismo.
Normalmente se usan pipes cuando dos procesos quieren correr en paralelo, con datos que se mueven de un proceso al otro en una sola dirección. Si la comunicación es bidireccional deben usarse mensajes.
El Administrador de Filesystem tiene varias características que contribuyen a que el acceso al disco sea de alto rendimiento:
Minimiza el tiempo global de búsqueda (seek) para leer o escribir los datos en el disco. Las demandas de I/O son ordenadas de tal forma que todas puedan ser atendidas con una sola barrida del cabezal del disco, de la dirección más baja del disco a la más alta.
Es un buffer inteligente entre el Administrador del Filesystem y el driver del disco. El caché de buffer intenta guardar bloques del filesystem para minimizar el número de veces que el Administrador del Filesystem tiene que acceder al disco. Por defecto, el tamaño del caché es determinado por la memoria total del sistema, pero usted puede especificar un tamaño diferente.
Cuando los datos entran en el caché, el Administrador del Filesystem avisa al cliente que los datos fueron escritos.
Las aplicaciones pueden modificar la conducta de escritura en un comportamiento de archivo por archivo. Esto aseguraría un nivel alto de integridad del archivo ante problemas potenciales de hardware o suministro de energía.
El Administrador del Filesystem es un proceso multi-hilo. Es decir, puede manejar varios pedidos de I/O simultáneamente. Esto le permite total aprovechamiento del potencial del paralelismo de la siguiente forma:
El Administrador del Filesystem puede tener su prioridad manejada por la prioridad de los procesos que le envían mensajes. Es decir cuando el Administrador del Filesystem recibe un mensaje, se le asigna la prioridad del proceso que realizó la petición.
Para este tipo de archivos, el Administrador del Filesystem intenta mantener los bloques de datos en la caché y escribirá los bloques de disco que sean absolutamente necesarios.
El Administrador de Filesystem tiene una capacidad de ramdisk integrada que permite que 8M de memoria puedan ser usados como un disco virtual. El Administrador del Filesystem es capaz de pasar por alto la cache de buffer por que el ramdisk esta incorporado a él y no necesita un driver.
QNX logra un filesystem de alto rendimiento sin sacrificar fiabilidad. Mientras la mayoría de los datos se almacena en el caché y son escritos después de un retraso corto, los datos críticos del filesystem se escriben inmediatamente. Las actualizaciones de los directorios, inodes, bloques extends, y de los bitmap se envían forzosamente al disco para asegurar que la estructura del filesystem en el disco nunca sea incoherente.
Para poder recuperar tantos archivos como sea posible, "firmas" únicas han sido escritas en el disco para ayudar ha identificar y recuperar automáticamente partes del filesystem críticos. Los archivos inodes (/ .inodes), así como cada directorio y extends blocks, contienen únicos modelos de datos, en donde la utilidad chkfsys se puede usar para volver a montar un filesystem dañados.
QNX considera cada disco físico como un archivo especial de bloque. Un disco se ve por el filesystem como un conjunto secuencial de bloques, de 512 bytes cada uno, sin tener en cuenta el tamaño y capacidad del disco. Se numeran los bloques, empezando con el primer bloque en el disco (bloque 1).
Cada subsistema del disco consiste en un controlador y en uno o más discos. Usted inicia el driver del dispositivo para cada subsistema del disco que será manejado por el Administrador de Filesystem.
QNX permite tener distintos SO sobre el mismo disco. De acuerdo con esto se puede definir una tabla de partición de hasta cuatro particiones primarias sobre el disco. La tabla se almacena en el primer bloque del disco.
Cada partición debe tener un "tipo" reconocido por el sistema operativo preparado para manejar la partición. Aquí se muestran los tipos de particiones que se usan usualmente:
Type | Filesystem |
1 | DOS (12-bit FAT) |
4 | DOS (16-bit FAT; partitions <32M) |
5 | DOS Extended Partition |
6 | DOS 4.0 (16-bit FAT; partitions >=32M) |
7 | OS/2 HPFS |
7 | Previous QNX version 2 (pre-1988) |
8 | QNX 1.x and 2.x ("qny") |
9 | QNX 1.x and 2.x ("qnz") |
11 | DOS 32-bit FAT; partitions up to 2047G |
12 | Same as Type 11, but uses Logical Block Address Int 13h extensions |
14 | Same as Type 6, but uses Logical Block Address Int 13h extensions. |
15 | Same as Type 5, but uses Logical Block Address Int 13h extensions |
77 | QNX POSIX partition |
78 | QNX POSIX partition (secondary) |
79 | QNX POSIX partition (secondary) |
99 | UNÍS |
Si se desea más de una partición de QNX 4.x en un solo disco físico, utilizaría el tipo de los 77 para su primera partición QNX. Se puede usar la utilidad fdisk para crear, modificar o borrar particiones.
Debido a que QNX trata a cada partición del disco como un bloque de archivos especiales, puede tener acceso a cualquiera de los siguientes:
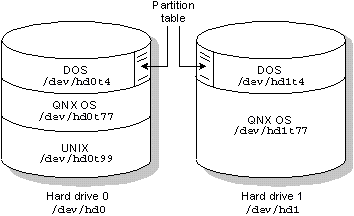
Dos unidades de disco físicas. El primer disco contiene particiones DOS, QNX y UNIX. El segundo disco contiene particiones DOS y QNX.
En el Administrador de filesystem se podría definir el archivo especial de bloque /dev/hd0 y /dev/hd1 para que las dos unidades inicien el driver.
A continuación se utiliza el comando mount para definir un bloque de archivo especial para cada partición. Por ejemplo:
mount -p /dev/hd0 -p /dev/hd1
Arrojaría el siguiente bloque de archivos especiales:
Partición SO: | Archivo Especial de Bloque |
Partición DOS en la unidad hd0 | /Dev/hd0t4 |
partición QNX en la unidad hd0 | /Dev/hd0t77 |
UNIX partición en la unidad hd0 | /Dev/hd0t99 |
DOS en la unidad HD1 | /Dev/hd1t4 |
QNX partición en el disco HD1 | /Dev/hd1t77 |
Tenga en cuenta que la tn se utiliza por convención para referirse a las particiones de disco utilizado por ciertos sistemas operativos. Por ejemplo, una partición de DOS es t4, una partición UNIX es t99, etc.
Para montar un sistema de archivos, uso el comando mount, que permite especificar el prefijo que identifica el sistema de ficheros. Por ejemplo:
mount /dev/hd0t77 /
Monta un sistema de archivos con un prefijo de / en la partición definida por el archivo especial de bloque llamado hd0t77. Para desmontarlo usaria:
umount /dev/hd0t77
Los componentes importantes se encuentran al principio de cada partición:
Estas estructuras se crean cuando usted inicializa el sistema de archivos con la utilidad del dinit.
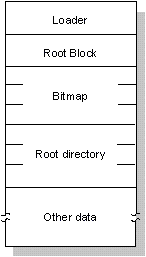
La estructura de un sistema de archivos en QNX dentro de una partición del disco
Este es el primer bloque físico de una partición del disco. Este bloque contiene el código que se carga y se ejecuta por el BIOS de la computadora para cargar un sistema operativo de una partición. Si un disco no se ha dividido (por ejemplo como en un floppy), este bloque es el primer bloque físico en el disco.
El bloque raíz se estructura como un directorio normal. Contiene la información del inode para estos cuatro archivos especiales:
Normalmente, el loader de QNX carga la imagen de OS guardada en el archivo /.boot. Pero si el archivo de /.altboot no está vacío, se dará la opción para cargar la imagen guardada en el archivo de /.altboot.
Para asignar el espacio en un disco, QNX usa un bitmap guardado en el archivo /.bitmap. Este archivo contiene un mapa de todos los bloques en el disco, indicando qué bloques están usados. Cada bloque se representa por un bit. Si el valor del bit es 1, su bloque correspondiente en el disco esta en uso.
Cuando un directorio o archivo se borra, la estructura de datos que lo representa es marcada como borrada, pero no se remueve la misma. Esto evita borrar continuamente y volver a escribir el medio.
Eventualmente, el medio se quedará sin espacio libre y el Administrador del sistema de archivos realizará el reclamo de espacio. Durante este proceso recupera el espacio ocupado por los archivos y directorios anulados.
El Sistema de Archivo de Red (NFS) es una aplicación de TCP/IP llevado a cabo en DOS y Unix. QNX soporta este tipo de sistemas de archivo. Usted necesita sólo usar NFS si está accediendo a sistemas de archivos que no son QNX NFS, o si usted quiere permitir a los clientes de NFS acceder al espacio de nombres de QNX. NFS le permite unir sistemas de archivos remotos, hacia su espacio de nombres local. Los directorios en los sistemas remotos aparecen como parte de su filesystem local y todas las utilidades que usted usa para listar y manejar los archivos (por ejemplo el ls, el cp, el mv) operan exactamente igual en los archivos remotos como lo hacen en sus archivos locales.
El Administrador de Dispositivos (Dev) es la interfase entre los procesos y los dispositivos terminales. Estos dispositivos terminales se localizan en el namespace de I/O con nombres que comienzan con /dev.
Por ejemplo, un dispositivo de consola tendría un nombre como:
/dev/con1
Un dispositivo terminal se presenta a un proceso como un flujo bidireccional de bytes que pueden leerse o escribirse por el proceso. Dev regula el flujo de datos entre una aplicación y el dispositivo. Parte del procesamiento de los datos es realizado por Dev según los parámetros en la estructura de control terminal (llamada termios), existe un ternio para cada dispositivo.
Los parámetros de los termios controlan las funcionalidades de bajo nivel, tales como:
La siguiente figura muestra un subsistema típico de un dispositivo.
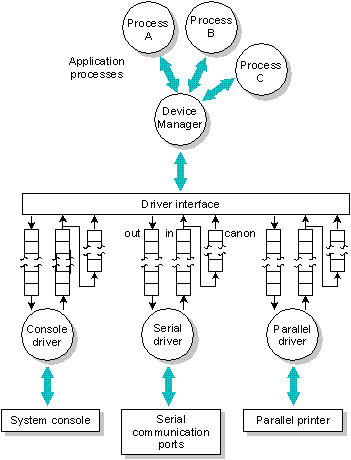
Dev maneja el flujo de datos desde y hasta los procesos de aplicación. La interfase del hardware se maneja por procesos de drivers individuales. Los datos fluyen entre Dev y sus drivers a través de un conjunto de colas de memoria compartida para cada dispositivo terminal. Ya que se usan colas de memoria compartida, es necesario que Dev y todos sus drivers residan en el mismo CPU, esto incrementa la performance.
Se usan tres colas para cada dispositivo. En cada cola se implementa FIFO y una estructura de control es asociada con cada cola. Los datos recibidos se ponen en la cola de entrada por el driver y sólo son consumidos por Dev cuando la aplicación procesa los datos demandados.
Los tamaños de todas estas colas son configurables por el administrador del sistema; la única restricción es que la suma de las tres colas no puede exceder los 64K. Los valores por defecto normalmente son más que adecuados para manejar la mayoría de las configuraciones del hardware.
Los drivers de dispositivos colocan los datos recibidos en la cola de entrada o los consumen y transmiten los datos de la cola de salida. Dev decide cuando será suspendida la transmisión de salida, y como realizar el eco de los datos.
Para asegurar una buena respuesta interactiva a eventos de entrada, Dev debe correr a una prioridad bastante alta. Los drivers son procesos como cualquier otro proceso en QNX; ellos pueden ejecutarse a prioridades diferentes según la naturaleza del hardware que sirvan
.
Las consolas de sistema son manejadas por el driver procesos "Dev.con". Los adaptadores de la placa de video, la pantalla, y teclado, se los denomina en su conjunto la consola.
QNX permite correr sesiones múltiples concurrentemente en la consola a través de consolas virtuales. El proceso del driver de la consola "Dev.con", típicamente maneja más de un conjunto de colas de I/O hacia Dev que están disponibles para los procesos del usuario como un conjunto de dispositivos terminales con nombres como /dev/con1, /dev/con2, etc.
El driver de las consolas corre como un proceso normal. Los caracteres de entrada por teclado son trazados por el driver de interrupciones del teclado y los coloca directamente en la cola de la entrada. Los datos de salida se consumen y despliegan por Dev.con.
¿QNX4 no soporta archivos Swap?
La principal razón de esto es que QNX4 requiere tiempos de respuesta y performance en tiempo real y tiene conflictos a la hora de implementar un archivo swap.
El requerimiento para swaping en la mayoría de las aplicaciones de QNX es bastante bajo. La eficacia del OS y el copilador de Watcom proporcionan pequeños procesos en término de requisitos de memoria. Cuando esto se combina con la habilidad de compartir el código entre las invocaciones de procesos múltiples y las bibliotecas compartidas, las demandas de memoria en QNX son bastante moderadas
¿QNX soporta memoria virtual?
Sí. No confunda esto con un archivo swap. La memoria virtual sólo se refiere al mapeo de memoria física a través de un MMU (Memory management unit). El uso de memoria virtual permite que QNX provea tanto, memoria compartida como protección de memoria entre procesos.
Mientras muchos de los kernels de tiempo real proveen soporte para la protección de memoria en tiempo de desarrollo, pocos lo hacen para el tiempo de ejecución, debido a la perdida de performance como principal razón.
La ventaja clave ganada por añadir memoria protegida, especialmente para sistemas de misión critica, es la robustez.
Con protección de memoria, si un proceso que se esta ejecutando en un ambiente multitarea intenta acceder a la memoria que no ha sido explícitamente declarada, el MMU puede notificar al sistema operativo, para que luego este pueda abortar el hilo.
MMU Memory management unit (unidad de gestión de memoria): Es un dispositivo de Hardware, responsable del manejo de los accesos a la memoria por parte de la CPU. Un MMU típico opera dividiendo la memoria física en páginas de 4K. El hardware del procesador luego hace uso de un conjunto de tablas almacenadas en la memoria del sistema que definen el mapeo de direcciones virtuales a las direcciones emitida por el CPU para acceder a la memoria física.
Mientras el hilo se ejecuta, direcciona la memoria como si lo hiciera en un sistema sin MMU, excepto que las tablas de paginas administradas por el sistema operativo controlan como estas direcciones se mapean en la memoria física.
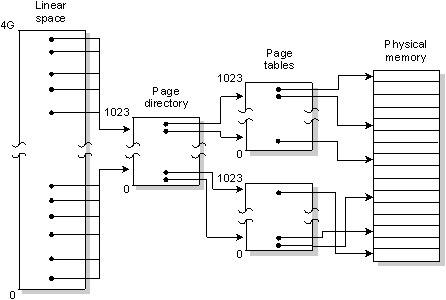
Para espacios de direcciones muy grandes con muchos procesos e hilos, el número de entradas en la tabla de páginas puede ser significativo (más de lo que puede almacenar el procesador). Para mantener la performance el procesador cachea frecuentemente las porciones usadas de las páginas de tablas en un TLB (translation look-aside buffer).
Los fallos de servicios en la caché TLB son parte de la sobrecarga impuesta por el uso de MMU. QNX usa varios arreglos inteligentes para minimizar esta sobrecarga.
Asociados a estas tablas de paginas hay bits que definen los atributos de cada pagina de memoria. Las páginas pueden ser marcadas como solo lectura, lectura-escritura, etc...
Cuando QNX ejecuta un cambio de contexto, manipula la MMU para usar potencialmente un conjunto nuevo de páginas para el nuevo hilo. Si se está cambiando entre hilos de un mismo proceso, no se requiere manipular la MMU.
El costo de performance por protección de memoria es insignificante en la mayoría de los sistemas. Quizás más importante es el incremento de costo de memoria para soportar las tablas de paginas MMU para implementar mayor nivel de protección.
El administrador de procesos ofrece la posibilidad de sin protección o protección total.


Comunicándose directamente con el Microkernel, Qnet mejora el intercambio de mensajes propagando los mensajes eficazmente a las máquinas remotas. Además, el Administrador de la Red ofrece tres características avanzadas:
Qnet es una red basada en el envío de mensajes que brinda acceso transparente a cualquier recurso del sistema. Qnet le permite construir aplicaciones eficientes y tolerantes a fallos que pueden ser escaladas fácilmente.
Qnet esta integrada en el corazón de las primitivas de manejo de procesos y envió de mensajes de QNX, haciendo que la intercomunicación de procesos local o por red sea lo mismo. Usando Qnet, una red de nodos individuales se convierte en una supercomputadora virtual, donde cada nodo tiene acceso a todos los recursos del sistema.
El diseño único de Qnet hace posible crear redes altamente escalables y tolerantes a fallo con soporte para balanceo la carga.
Con Qnet, cualquier dispositivo en el sistema puede acceder a cualquier recurso en forma transparente. Qnet extiende el mecanismo de envió de mensajes que forma el núcleo de la plataforma QNX. Utilizando Qnet, los mensajes son enviados de forma transparente de un nodo a otro, lo que hace posible acceder y utilizar recursos de distintos nodos en forma transparente.
El Administrador de Red no tiene que ser construido en la imagen del sistema operativo. Puede ser iniciado y detenido en cualquier momento para proporcionar o anular las capacidades de mensajería de red.
Cuando Qnet inicia, se registra con el Administrador de Procesos y con el Microkernel. Esto activa el código existente dentro de las dos interfases con el Administrador de la Red. Esto significa que la mensajería de red y la creación de procesos remotos no sólo es una capa agregada al sistema operativo.
Esta profunda integración a bajo nivel le da transparencia a la red, y lo califica como un sistema operativo totalmente distribuido. Ya que todas las aplicaciones acceden a los servicios vía mensajes, el Administrador de Red permite que los mensajes fluyan transparentemente en la red, los nodos de QNX trabajan juntos como una sola supercomputadora lógica.
Como el Administrador de Filesystem y el Administrador de Dispositivos, el Administrador de Red no contiene ningún código de hardware específico. Esta funcionalidad es proporcionada por los drivers de la tarjeta de red. El Administrador de Red puede soportar múltiples drivers de tarjetas de red a la vez. Cada Driver soporta una sola tarjeta de red.
Las colas de memoria compartida proporcionan la interfase entre el Administrador de Red y los drivers. El driver determina el protocolo apropiado para los medios de comunicación en la red.
Los Driver son responsables de la packetización, la secuencia y de la retransmisión (en caso de que un nodo solicite la retrasmisión). Esto le permite a QNX soportar fácilmente nuevos hardware de red y protocolos, escribiendo o modificando solamente los Drivers de red.
El rendimiento de la red es determinado por la velocidad del nodo y la de la red. Si un nodo puede proporcionar datos más rápido que los que puede aceptar la red, entonces la red limitará el rendimiento.
El Administrador de Red equilibrará automáticamente la carga escogiendo un driver de red apropiado.
Cuando ahí nodos conectados a dos o mas redes, existe más de un camino a usar para la comunicación. Si una tarjeta en una red falla el Administrador de la Red re-dirigirá todos los datos automáticamente a través de la otra red. Esto pasa automáticamente sin ningún tipo de intervención por parte del software de aplicación, resultando la tolerancia a fallos de la red totalmente transparente. Si se colocan diferentes cables para las diferentes redes, usando rutas separadas, también se protegerá contra cortes de cables accidentales. También se pueden construir sistemas en tándem, en los que dos máquinas son conectadas por una red rápida para su normal funcionamiento y otra red más barata y más lenta queda de respaldo.Si la primera red falla, la comunicación continuará, aunque se reduciría el rendimiento.
Qnet permite alto rendimiento y tolerancia a fallos a través del soporte para múltiples enlaces entre nodos. Dependiendo de las necesidades del sistema, se puede elegir entre tres clases de servicios:
Cada nodo en una red de área local es identificado por dos números:
Con Qnet, es fácil crear redes altamente escalables. La misma aplicación puede correr en un único procesador o ser distribuida a través de múltiples procesadores. No se requiere modificación alguna y debido a que las aplicaciones no requieren código especifico para manejar la red, nuevas redes (Ethernet, serial, backplane) pueden ser introducidas, sin recodificar aplicaciones.
El Administrador de Red permite a cualquier nodo actuar como bridging entre dos redes IEEE 802.
Ya que QNX usa el mismo formato de paquetes y protocolos en todas las redes IEEE 802, se puede crear bridging entre redes Ethernet, Token Ring, y FDDI. No pueden puentearse las redes de Arcnet.
Son soportados los siguientes protocolos de red ARP, IP, ICMP, UDP, TCP, entre otros.
QNX implementa su propio protocolo de red, el cual esta optimizado para proporcionar una rápida, e idéntica interfase entre computadoras basadas en QNX. Pero para comunicarse con sistemas que no utilizan QNX, utiliza TCP/IP.
El Administrador TCP/IP se basa en Berkeley BSD 4.3, que es la pila TCP/IP más común en Internet y es usada como base para muchos sistemas.
NFS es una aplicación TCP/IP implementada en sistemas DOS y Unix. NFS permite unir filesystems remotos (o partes de ellos) en un espacio de nombres locales. Los archivos en los sistemas remotos aparecen como parte del filesystem local de QNX.
QNX también soporta SMB Server Message Block (Bloques de Mensajes del Servidor) es un protocolo para compartir archivos, usado por diferentes servidores como Windows NT Windows 95, Windows para Workgroups, LAN Manager, y Samba. El filesystem de SMBfsys permite a un cliente QNX acceder a los archivos remotos que residen en tales servidores transparentemente.
Con el navegador Voyager, la interfase y el motor son dos programas separados. Esto crea una arquitectura cliente/servidor donde la interfase (cliente) dialoga con el motor del navegador (servidor) a través de una interfaz llamada PtWebClient.
Con una arquitectura como esta es muy fácil la personalización. Para modificar la interfaz del navegador, simplemente se modifica el PtWebClient.
Si usted necesita un navegador WEB para su sistema embebido y no desea desperdiciar tiempo y dinero en construir uno, el navegador Voyager es para usted. Esta completamente equipado y es altamente modular, puede correr en modo completo o compacto. Puede escalarlo desde un navegador básico con un manejo de memoria optimizado hasta incluir soporte para múltiples idiomas.
Controle remotamente su fotocopiadora, reciba estadísticas de cualquier dispositivo desde su navegador con el servidor WEB. Suficientemente pequeño para una impresora láser, y robusto para un robot de fábrica, este servidor le permite incluso a sistemas embebidos sin disco generar páginas dinámicas en tiempo real.
FLEET es una característica única de QNX que crea un conjunto homogéneo de recursos que se pueden acceder en forma transparente, desde cualquier lugar de la red. FLEET es un protocolo de red ultra liviano y de alta velocidad. Hace que todos los nodos conectados se vean como un solo supernodo lógico. Como FLEET se construye sobre la arquitectura de comunicación entre mensajes de QNX, ofrece lo último en flexibilidad. FLEET proporciona:
Si un cable o tarjeta de red en una red falla, FLEET automáticamente rutea los datos a través de otra red. Esto pasa en la red, sin involucrar software de aplicación, dándole automática tolerancia a fallos de red.
El rendimiento de la red está normalmente limitado por la velocidad del nodo y por el hardware de red. Con FLEET, pueden transmitirse datos simultáneamente sobre múltiples redes, permitiéndole doblar, triplicar, o incluso cuadruplicar el ancho de banda y el rendimiento, poniendo múltiples tarjetas de red en cada computadora y conectándolas con cables separados.
Se puede combinar distintos tipos de tarjetas de red incluso (ej. Ethernet, FDDI) en la misma máquina.
Los drivers de red FLEET son construidos para realizar la gran parte del hardware de gestión de redes. Por ejemplo, al enviar bloques grandes de datos en una red de Ethernet de un proceso a otro, usted obtendrá:
Tipo de red | No. de procesos del cliente | Rendimiento |
10 Mbit Ethernet | 1 | 1.1 Mbytes/sec |
100 Mbit Ethernet | 1 | 7.5 Mbytes/sec |
Gracias a FLEET, la red QNX tiene excelente flexibilidad. Los procesos de una red de nodos son arquitectónicamente distintos que los procesos del OS, permitiéndole empezar y detener un nodo conectado en cualquier momento. Esto significa que usted puede agregar nodos a su red o puede quitarlos dinámicamente sin reconfigurar su sistema. Y, gracias al puenteo automático de red, se puede agregar redes físicas diferentes a la LAN.
Los procesos de red de FLEET están integrados en el corazón del pasaje de mensajes y primitivas de administración de procesos, haciendo que el ancho de red IPC y local sea el mismo. Puesto que IPC es transparente, un conjunto de nodos aparece como uno solo. Por ende no se tiene que modificar las aplicaciones para poder comunicarse por la red.
Muchos sistemas embebidos requieren una interfaz de usuario para interactuar con las aplicaciones. Para simplificar las complejas interfaces de usuario, un sistema gráfico de ventana es una elección natural. Sin embargo, los sistemas de ventanas en las PC de escritorio simplemente requieren demasiados recursos para ser practicos en un sistema embebido que tiene limitaciones de memoria y costo. A continuación se detalla la arquitectura única de Photon microGUI, un sistema de ventana escalable que corre con menos de 500K de memoria y sin embargo entrega toda la funcionalidad esperada de un sistema de ventanas e introduce muchas opciones de conectividad.
Photon microGUI ha sido diseñado para entregar un sistema grafico de ventanas a ambientes con restricciones de recursos. A través de su única arquitectura provee:
Enlaces
[1] https://francisconi.org/qnx/diseno#comment-form
[2] https://francisconi.org/qnx/algunos-ejemplos-rtos#comment-form
[3] https://francisconi.org/qnx/administrador-prefijos-io#comment-form
[4] https://francisconi.org/qnx/administrador-del-filesystem#comment-form
[5] https://francisconi.org/qnx/bloque-loader#comment-form